이번에는 자연어 처리를 위해 단어들을 어떤 식으로 모델이 처리할 수 있는 데이터인 벡터로 바꿀 수 있을지에 관한 기법인 Word2Vec에 대해 알아보도록 하겠습니다.
먼저 단어들을 모델이 처리할 수 있는 데이터로 바꾸는 방법에는 대표적으로 One-Hot-Encoding과 Word Embedding이 있습니다.
One-Hot-Encoding
One-Hot-Encoding은 단어별로 index를 부여해서 표현하고자 하는 단어에 1을 나타내는 기법입니다.
예를들어, 단어가 A, B, C, D 총 4개가 있고 각각에 차례대로 index를 부여하고, 이때, A를 표현하고자 하면 [1,0,0,0]으로 표현이 가능합니다.
이러한 방법의 장점은 직관적이고 구현이 간편하다는 장점이 있지만,
단점으로는 단어의 개수가 곧 차원이 되므로 나타낼 단어가 많아질수록 차원이 높아져 연산량이 과도하게 많아 학습이 느려진다는 단점이 있습니다. 또한 상관관계와 같은 단어들간의 관계들을 나타낼 수 없다는 단점 또한 있습니다.
위 단점들을 어떻게 해소가 가능할까요..?? 바로 아래에 알아볼 Word Embedding에 답이 있습니다.
Word Embedding
Word Embedding은 단어의 의미를 고려해서 밀집 벡터에 표현하는 방식입니다.
단어들간의 관계를 고려할 수 있을 뿐만 아니라 단어의 수가 많아져도 차원이 높아지지 않는다는 장점이 있습니다.
Word Embdding은 어떻게 수행되는 것일까요?? Word2 Vec, FastText 등등 여러 가지 방법이 있지만, Word2 Vec 기법에 대해서 알아보도록 하겠습니다.
Word2Vec
Word2Vec 기법은 학습을 통해서 벡터에 단어를 나타냅니다.
이렇게만 들으면 이해가 잘 되지 않을 수 있으므로 Word2Vec에서는 어떻게 Word Embedding을 수행하는지 알아보도록 하겠습니다.
Word2Vec 기법에는 또 종류가 여러 가지가 있는데 주변 단어를 통해서 중심 단어를 예측하는 방식으로 동작하는 CBOW, 중심단어를 통해서 주변단어를 예측하는 방식으로 동작하는 Skip-Gram 방식이 있습니다.
먼저 CBOW를 기준으로 살펴보겠습니다.
CBOW
CBOW는 주변단어를 통해 중심단어를 예측하는 방식입니다.
The fat cat sat on the mat라는 문장을 예시로 들어보겠습니다.
Window의 크기는 2라고 가정을 하겠습니다. CBOW에서 window의 크기란 중심 단어를 기준으로 앞뒤 몇단어를 입력받을지에 대한 값입니다. (1인경우 중심단어를 기준으로 앞으로 한 단어, 뒤로 한 단어를 주변 단어로 사용합니다)
만약 앞 뒤 두 단어를 기준으로 한다면, 이런식으로 앞의 두단어, 뒤의 두단어를 입력으로 받고 중심 단어를 예측하는 방식으로 동작합니다.
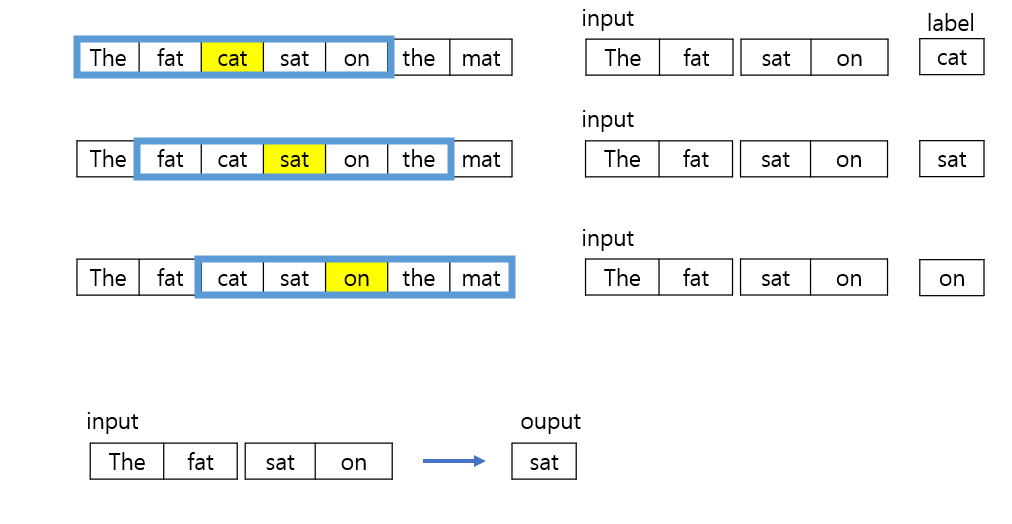
그럼 실제로는 어떻게 학습을 시키고 예측을 하는지 살펴보도록 하겠습니다.
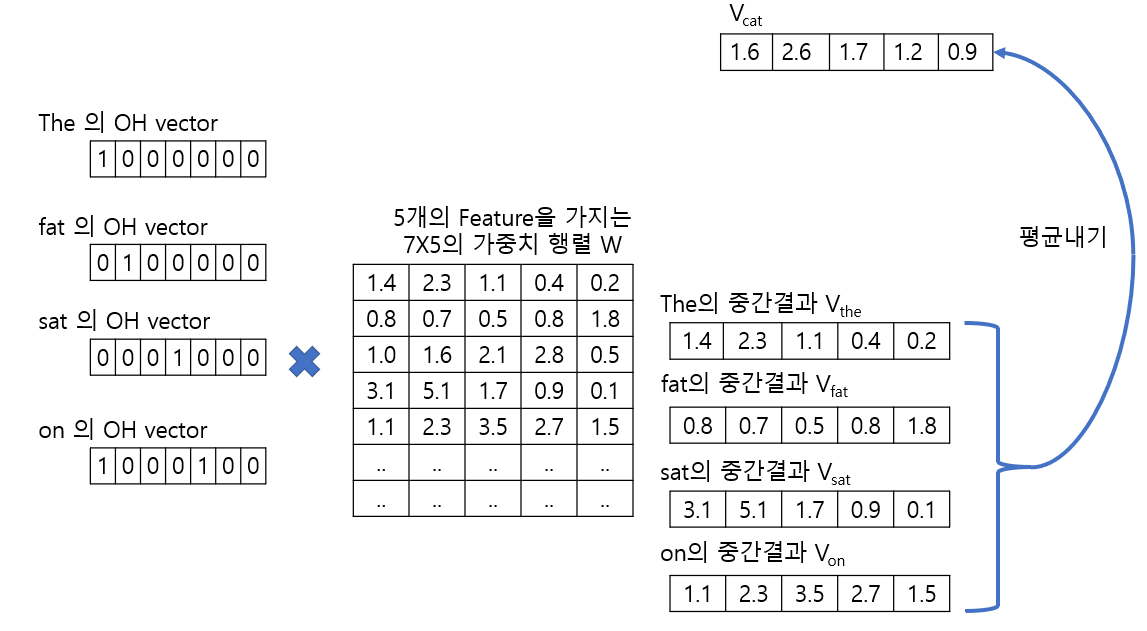
1. 먼저 각 단어 별로 One-Hot-Encoding을 통해 Sparse Vector를 만들어주고
2. 이러한 벡터를 가중치 행렬과 행렬곱을 통해 해당 단어(cat)를 제외한 단어들, 즉 주변 단어(The, fat, sat, on)의 Embedding Vector를 만들어 줍니다.
3. 그 후 그 벡터들을 평균 내서 해당 단어(cat)에 대한 Embedding Vector(V_cat)로 만듭니다.
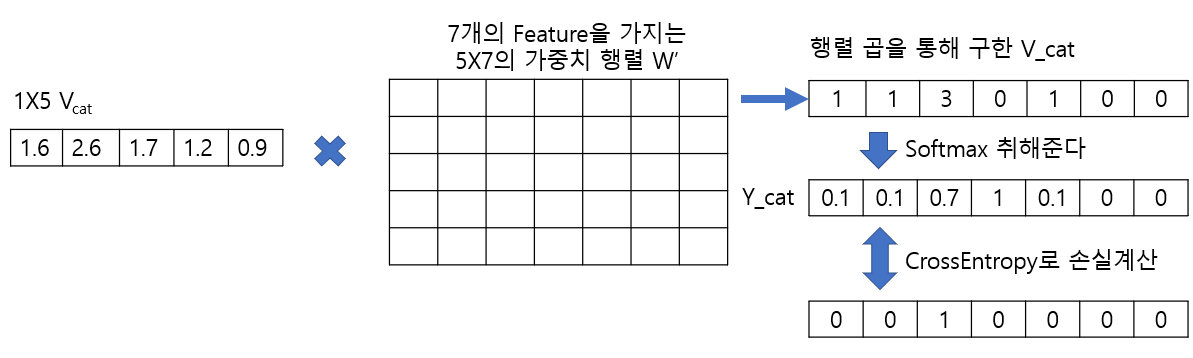
4. 3번 과정에서 만든 벡터(V_cat)를 W'와(W와는 다른 행렬이다) 행렬곱을 하고 softmax를 취해 최종 출력(y_cat)을 구합니다.
5. 최종 출력(y_cat)을 해당 단어(cat)의 Sparse Vector과 비교해 CrossEntropy로 손실을 계산합니다.
6. 손실을 바탕으로 역전파를 통해 W와 W'의 가중치를 학습시킵니다.
7. 학습이 끝나면 Embedding Vector으로 W 혹은 W, W' 둘다를 사용합니다.
*주의해야할 점은 "W'는 W의 전치행렬이 아니다"라는 것입니다.
(학습 초기 W'와 W는 임의의 값으로 주어집니다.)
그림으로 살펴보면 다음과 같습니다.
Skip-Gram
이번에는 CBOW와는 반대로 중심 단어를 통해 주변 단어를 예측하는 방식인 Skip-Gram 방식에 대해 알아보도록 하겠습니다.
CBOW를 이해하셨다면은 Skip-Gram을 이해하는데 크게 어려움이 없을 것으로 예상됩니다.
Skip-Gram 방식은 중심 단어(cat)를 One-Hot-Encoding 한 sparse vector를 W와 행렬 곱을 하고 W'와 행렬 곱을 한 값에 softmax 취해준 y_cat과 나머지 주변 단어(The, fat, sat, on)들을 One-Hot-Encoding 한 Sparse Vector들을 각각 CrossEntropy로 손실을 계산해주면서 학습을 진행하게 됩니다.
이번 시간에는 단어를 모델이 처리할 수 있는 구조로 바꾸는 방법 중 하나인 Word Embedding에서도 Word2 Vec 기법에 대해 배웠습니다. 혹시 잘 모르겠거나 틀린 부분이 있는 경우 언제든 댓글로 달아주시면 감사하겠습니다!!
참조
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
Word2Vec의 학습 방식 · ratsgo's blog
이번 포스팅에서는 최근 인기를 끌고 있는 단어 임베딩(embedding) 방법론인 Word2Vec에 대해 살펴보고자 합니다. Word2Vec은 말 그대로 단어를 벡터로 바꿔주는 알고리즘입니다. Neural Network Language Model(
ratsgo.github.io
https://heytech.tistory.com/352
[NLP] Word2Vec: (2) CBOW 개념 및 원리
📚목차 1. 학습 데이터셋 생성 2. 인공신경망 모형 3. 학습 절차 4. CBOW vs Skip-gram 5. 한계점 들어가며 Word2Vec는 학습방식에 따라 크게 \(2\)가지로 나눌 수 있습니다: Continuous Bag of Words(CBOW)와 Skip-gram.
heytech.tistory.com
09-02 워드투벡터(Word2Vec)
앞서 원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점이 있음을 언급한 적이 있습니다. 그래서 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를…
wikidocs.net
'수업내용정리 > 인공지능' 카테고리의 다른 글
| [Tensorflow][Keras]Conv2D사용법 _CNN이란? (0) | 2023.01.17 |
|---|---|
| [Tensorflow][Keras]CNN이란? CNN에 대해 개략적으로 살펴보기 (0) | 2023.01.15 |
| [Tensorflow][Keras]인공지능? 머신러닝? 딥러닝? (0) | 2022.12.09 |
| [Tensorflow][Keras]Word2Vec 코드로 구현하기 (0) | 2022.11.27 |
| [TensorFlow][Keras]ImageDataGenerator 사용법 (0) | 2022.11.24 |



