저번 시간에는 Word Embedding 기법 중에서 Word2 Vec라는 기법이 무엇인지에 대해 알아보았습니다. 이번 시간에는 실제로 Tensorflow의 Keras를 사용해서 실제로 텍스트 데이터를 Word2Vec기법을 사용해 Embedding Vector으로 바꾸는 방법에 대해 알아보도록 해보겠습니다.
필요한 라이브러리
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.processing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding
위 라이브러리들을 차례대로 설명하자면,
문장을 단어의 인덱스 배열들로 바꾸어주는 Tokenizer,
그렇게 만들어진 배열들의 길이를 똑같이 맞춰주는 pad_sequences
배열들을 밀집 벡터, 즉 Embedding Vector들로 바꾸어주는 Embedding 레이어입니다.
이렇게 글로만 보면 이해가 잘 되지 않을 테니 한번 예제를 이용해서 과정을 이해해보도록 하겠습니다.
데이터 가져오기
먼저 우리는 Kaggle이라는 사이트의 데이터를 이용할 예정입니다.
Kaggle에 접속해 Datasets 탭으로 들어가 줍니다.
https://www.kaggle.com/datasets
Find Open Datasets and Machine Learning Projects | Kaggle
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
www.kaggle.com
그리고 아래에 보라색 표지를 가진 IMDB Review Dataset을 클릭해줍니다.

그리곤 New Notebook을 클릭해서 데이터를 가져옵니다.

데이터를 가져왔으니 이제 데이터를 이용해서 읽어보도록 하겠습니다.

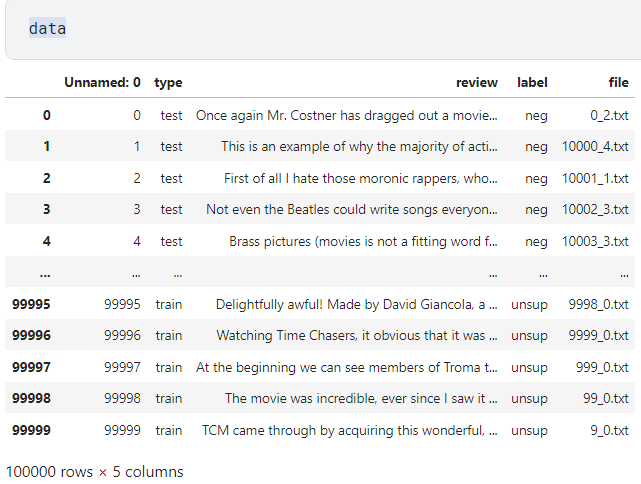
우리가 가져온 데이터는 이런 형식으로 구성이 되어 있음을 알 수 있습니다.
데이터 전처리
이제 본격적인 학습을 위해서 train 데이터와 test데이터, 그리고 label의 개수와 분포는 어떻게 이루어져 있는지 알아보도록 하겠습니다.
label의 경우 unsup이 5만, neg와 pos가 각각 2만 5천 개로 분포하고 있습니다.

그렇다면 type, 즉 train과 test의 분포는 어떻게 되어있을지 확인해봅시다.
확인 결과, train 데이터 7만 5천 개, test데이터 2만 5천 개가 있음을 확인할 수 있습니다.

이제, train데이터와 test데이터를 분리하도록 해보겠습니다.
test와 train의 분포를 확인해보니, test는 0번째부터 24999번째까지의 index의 데이터였으며, train은 25000번째부터 99999번째 index의 데이터임을 확인이 가능하였습니다. 이런 경우, 그냥 index에 따라 분리만 해주면 되기에 분리가 매우 간단합니다.
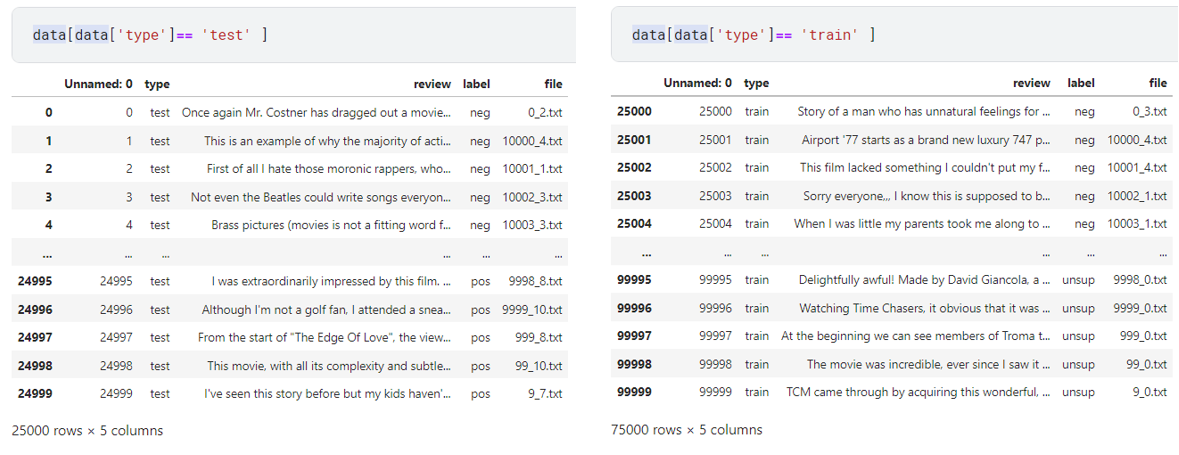
다만, 분리해주기 전에 label이 unsup인 경우를 제외해주기 위해서, 다음과 같이 unsup인 경우를 탐색해 줍니다.

unsup의 경우 5만 번째부터 99999번째 index까지의 데이터인 경우라는 것이 확인되었습니다. 즉 train데이터는 25000부터 49999 번째 index까지만 해당하도록 만들어 주면 됩니다.
이런 식으로 train과 test의 분리가 간단하게 이루어졌습니다.
(다만 위에서 확인했듯이, 이 데이터는 5만 번째 index부터는 label이 unsup 인 것을 알 수 있습니다.)

한번, train과 test가 잘 분리되었는지 확인해 봅시다.
잘 분리가 되었음을 확인이 가능합니다.

이제 처리하기 쉽도록 꼴을 바꾸어 줄 것입니다.
먼저, 다시 train와 test를 합치고 review라는 데이터 프레임을 만들어주고 이 프레임을 이용해서 단어들의 밀집 벡터를 만들어 보도록 하겠습니다.

review0이 잘 만들어졌음이 확인되었습니다.
이제 이 review0을 가지고 Embedding Vector으로 만들어 주도록 하겠습니다.
tensorflow.keras.preprocessing.text.Tokenizer
Tokenizer은 문장을 단어들을 정수인 index로 바꾸어 정수 배열로 바꿔주는 도구로써, 이 도구를 사용하기 위해서 이렇게 import 해줍니다.
from tensorflow.keras.preprocessing.text import Tokenizer
tk = Tokenizer()
그리곤 문장들을 정수 배열들로 바꾸어주기 위해 다음과 같은 작업을 수행합니다.
tk.fit_on_texts(review0)
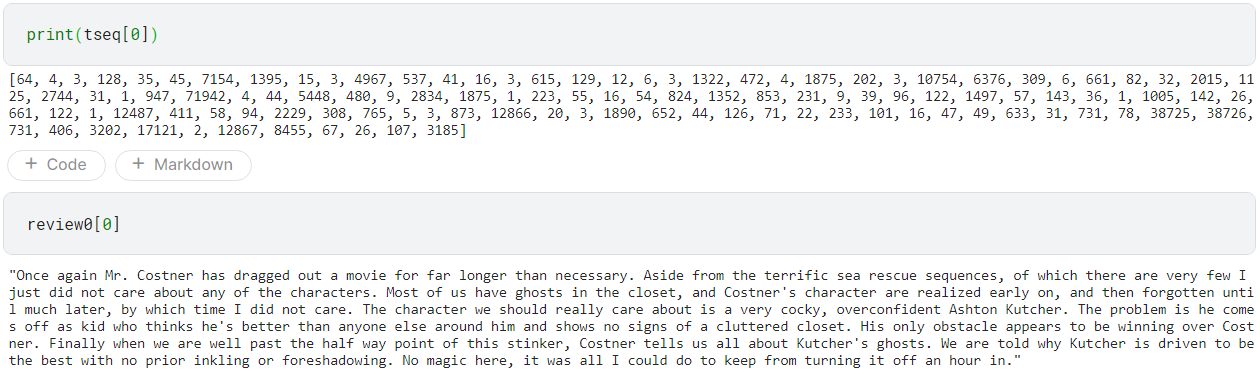
tseq = tk.texts_to_sequences(review0)
위의 작업을 통해 아래의 review0[0]이 단어 index의 배열인 tseq[0]으로 잘 변환이 되었음을 확인이 가능합니다.
이제, 이렇게 만들어진 배열들의 길이를 다 일정하게 만들어주도록 다음 코드를 실행해 줍니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
tpad = pad_sequences(tseq)
잘 실행되었음을 확인이 가능합니다. 이제 Embedding을 통해 Embedding Vector으로 만들어 보도록 하겠습니다.

아래와 같은 과정을 따라 진행하면은..
(tk.word_index 는 위의 tokenizer에서 모든 단어에 대해서 index:단어꼴로 나타낸 딕셔너리이다.)
from tensorflow.keras.layers import Embedding
embeddings = Embedding(input_dim = len(tk.word_index) ,output_dim=5)
#input_dim 에는 단어의 차원, 즉 단어의 개수가 들어가야한다.
#그러므로 len(tk.word_index)가 들어가야한다.
#output_dim 은 단어 하나당 몇차원의 embedding vector으로 나타낼지를 의미한다.
embedding_vectors = embeddings(tpad[0])
이렇게 5차원의 Embedding Vector들이 나옵니다.

이번 시간에는 실제 코드를 이용해서 문장을 Embedding Vector으로 바꾸는 방법에 대해서 알아보았습니다. 다음 시간에는 이런 코드를 응용해서 실제로 자연어 처리를 어떻게 하는지에 대해 알아보도록 하겠습니다. 감사합니다.
혹시 이해하기 어려운 부분이 있다거나 잘못된 부분이 있으면 언제든지 댓글로 달아주시면 감사하겠습니다!!
참조
https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer
tf.keras.preprocessing.text.Tokenizer | TensorFlow v2.11.0
Text tokenization utility class.
www.tensorflow.org
https://keras.io/ko/preprocessing/text/
Text Preprocessing - Keras Documentation
텍스트 전처리 [source] Tokenizer keras.preprocessing.text.Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~ ', lower=True, split=' ', char_level=False, oov_token=None, document_count=0) 텍스트 토큰화 유틸리티 클래스. 이
keras.io
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Embedding
tf.keras.layers.Embedding | TensorFlow v2.11.0
Turns positive integers (indexes) into dense vectors of fixed size.
www.tensorflow.org
https://keras.io/ko/layers/embeddings/
Embedding Layers - Keras Documentation
[source] 임베딩 keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None) 양의 정수(색인)를 고정된
keras.io
'수업내용정리 > 인공지능' 카테고리의 다른 글
| [Tensorflow][Keras]Conv2D사용법 _CNN이란? (0) | 2023.01.17 |
|---|---|
| [Tensorflow][Keras]CNN이란? CNN에 대해 개략적으로 살펴보기 (0) | 2023.01.15 |
| [Tensorflow][Keras]인공지능? 머신러닝? 딥러닝? (0) | 2022.12.09 |
| [Tensorflow][Keras][NLP]Word2Vec 이란? (0) | 2022.11.26 |
| [TensorFlow][Keras]ImageDataGenerator 사용법 (0) | 2022.11.24 |



