저번 시간에는 노래 하나의 가사만 추출하는 작업에 관해 다루었다.
이번 시간에는 노래 하나에 대해서만 수행했던 작업들을 차트의 모든 곡들에 대해 수행하고
이러한 데이터들을 가공하기 쉬운 꼴로 만들어줄 예정이다.
0. find_element와 find_elements의 차이점
시작하기 전에 find_element와 find_elements의 차이점에 대해 짚고 가도록 하겠다.
find_element와 find_elements의 차이점은 요소를 찾을 때 조건에 해당하는 요소가 여러 개인 경우,
혹은 조건에 해당하는 요소가 하나도 없는 경우 동작 방식에 있다.
find_element의 특징
먼저, find_element는 조건에 해당하는 요소가 여러 개일 경우, 웹문서의 제일 위에 있는 요소 하나만 반환하며,
조건에 해당하는 요소가 없는 경우, 에러를 띄운다.

find_elements의 특징
find_elements의 경우 조건에 해당하는 요소가 여러 개 일 경우, 해당하는 요소들을 리스트 안에 담아 반환하며,
조건에 해당하는 요소가 없는 경우 에러를 띄우지 않고 빈 리스트를 반환한다는 차이점이 있다.

1. 모든 차트에 대해 동작하게 만들기
웹드라이버 설치 및 설정 등 환경 세팅의 작업은 모두 미리 행해졌다는 가정하고 진행하도록 하겠다.

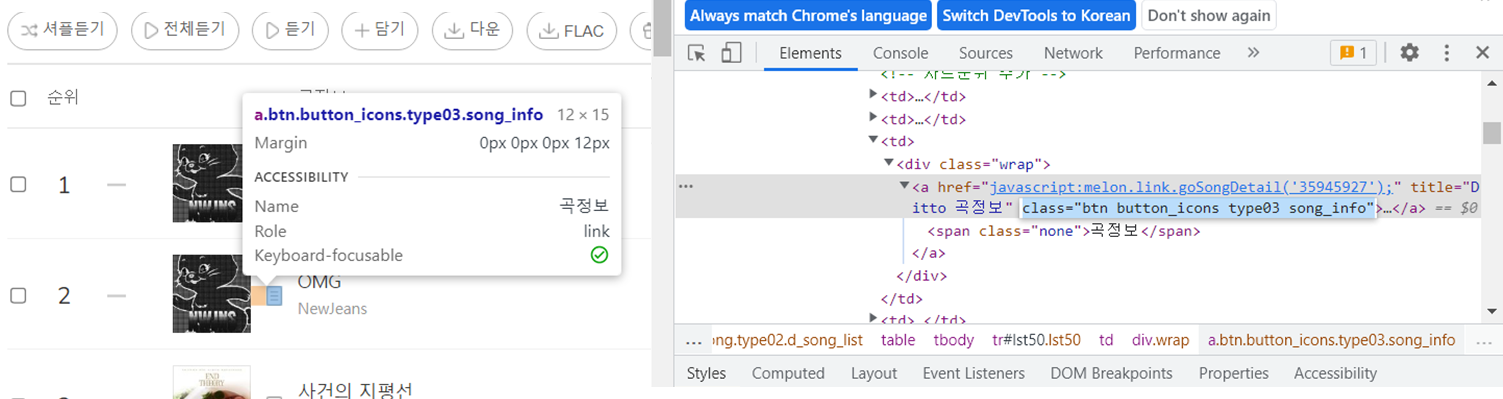
차트의 노래들의 곡정보 더 보기 버튼은 모두 btn button_icons type03 song_info의 클래스를 가짐을 알 수 있다.
즉 우리는 CSS 실렉터로. btn.button_icons.type03.song_info로 곡정보 더 보기 버튼요소들을 저장해 놓을 수 있다.
다음 과정은 저번시간과 마찬가지로 곡정보 버튼을 누르고 가사 펼치기 버튼을 누른 뒤 가사를 추출해주면 된다.
노래가사 추출이 끝이 나면 이전페이지로 돌아오고 다음 곡의 곡정보 더 보기 버튼을 클릭해주고 가사를 가져오는 작업을 반복해주면 된다.
뒤로 가기는 어떻게 할 수 있는가? driver.back()을 통해서 웹페이지에서 뒤로 가기와 같은 행위를 수행할 수 있다.
위 과정들을 코드로 정리하면 다음과 같다.
from selenium.webdriver.common.by import By
import time
import pandas as pd
driver.get("https://www.melon.com")
driver.find_element(By.CSS_SELECTOR, ".menu_bg.menu01").click()
time.sleep(1)
driver.find_element(By.CSS_SELECTOR,".menu_chart.m2").click()
more_info_list = driver.find_elements(By.CSS_SELECTOR,".btn.button_icons.type03.song_info")
lyrics = []
songs = []
artists = []
data = pd.DataFrame()
for i in range(0, 20):
more_info_list = driver.find_elements(By.CSS_SELECTOR,".btn.button_icons.type03.song_info")
more_info_list[i].click()
time.sleep(0.2)
song = driver.find_element(By.CSS_SELECTOR,".song_name")
songs.append(song.text)
time.sleep(0.2)
artist = driver.find_element(By.CSS_SELECTOR,".artist_name")
artists.append(artist.text)
driver.find_element(By.CSS_SELECTOR,".button_more.arrow_d").click()
time.sleep(0.2)
lyric = driver.find_element(By.CLASS_NAME,"lyric.on")
lyrics.append(lyric.text)
driver.back()
의도한 대로 잘 수행되었음을 아래에서 확인이 가능하다.

2. 가공하기 쉽게 데이터 프레임으로 만들기
앞선 과정에서 노래가사들을 lyrics에, 가수명은 artists에, 노래제목은 songs라는 리스트에 담아두었다.
리스트에 담은 데이터들을 한눈에 보기 쉽게 데이터 프레임으로 만드는 과정은 쉽다.
아래와 같이 pandas를 import 하고 data라는 DataFrame을 만들어준 뒤
열 이름을 정해주고 그에 해당하는 리스트를 넣어주면 된다.
import pandas as pd
data = pd.DataFrame()
data["song"] = songs
data["artist"] = artists
data["lyric"] = lyrics
DataFrame이 잘 생성되었음을 알 수 있다.

이번 시간에는 노래 하나에 대해서만 수행했던 작업들을 차트의 모든 곡들에 대해 수행하고
이러한 데이터들을 가공하기 쉬운 꼴인 데이터프레임으로 만들어 주는 작업을 했다.
이로써 멜론 노래 가사 추출하기 시리즈는 끝이났다.
다음시간에는 이렇게 만든 데이터 프레임을 분석을 하고
해당 데이터프레임을 활용한 AI 노래가사 만들기를 한번 해보려고 한다.
'개인프로젝트' 카테고리의 다른 글
| [홈서버]홈 서버란 무엇인가? - 나만의 서버 구축기 #0 (2) | 2025.03.20 |
|---|---|
| [Python]추출한 멜론 노래 가사로 워드클라우드 만들기 with 캐글 (0) | 2023.01.09 |
| [Python]멜론 노래 가사 추출하기(3)_셀레니움으로 노래가사 찾기 with 캐글 (4) | 2023.01.04 |
| [Python]멜론 노래 가사 추출하기(2)_셀레니움은 어떻게 요소들을 찾는가? with 캐글 (2) | 2023.01.02 |
| [Python]멜론 노래 가사 추출하기(1)_크롤링준비하기 with 캐글 (0) | 2022.12.31 |



