https://all4null.tistory.com/25
[Python]멜론 노래 가사 추출하기(4)_수집한 데이터 가공하기 with 캐글
저번 시간에는 노래 하나의 가사만 추출하는 작업에 관해 다루었다. 이번 시간에는 노래 하나에 대해서만 수행했던 작업들을 차트의 모든 곡들에 대해 수행하고 이러한 데이터들을 가공하기 쉬
all4null.tistory.com
저번시간. 위 글에서 셀레니움을 이용한 크롤링을 통해 멜론 노래 가사들을 추출해 냈었다.
이번 시간에는 우리는 추출한 노래 가사들을 가지고 워드클라우드를 만들어
어떤 단어가 많이 쓰였는지 확인해볼 예정이다.
워드클라우드란?
데이터에서 얻어진 요소들의 중요도나 인기도 등을 고려하여 시각적으로 늘어놓은 형태를 의미한다.
파이썬에선 어떻게 사용?
파이썬에서는 WordCloud라고 워드클라우드를 쉽게 만들어주는 라이브러리가 있다.
사용하려면 from wordcloud import WordCloud을 통해 사용이 가능하다.
가사 토큰화
먼저 추출한 가사들을 쪼개서 단어 형태로 만들어 주어야 하는데,
케라스의 Tokenizer을 사용해 이 작업을 수행해줄 예정이다.
**노래가사들을 추출해서 만든 data라는 데이터 프레임이 있다고 가정한 상태에서 시작한다**
**만약 없다면 이글 맨 위의 글을 참고하길 바란다.**
#가사들을 단어로 토큰화 하기
from tensorflow.keras.preprocessing.text import Tokenizer
tk = Tokenizer()
tk.fit_on_texts(data['lyric'])
그리고 Tokenizer의 word_counts를 통해서 단어와 해당 단어의 사용 빈도를 각각 key와 value로 갖는 딕셔너리를 얻을 수 있다.

이제 이 딕셔너리를 통해 워드클라우드를 만들 수 있다.
워드클라우드 만들기
워드클라우드는 기본적으로 아래와 같은 방법으로 사용이 가능하다.
from wordcloud import WordCloud
wc = WordCloud(font_path="폰트경로",
background_color="배경색상",
max_font_size=최대폰트크기,
width=너비,
height=높이)
cloud = wc.generate_from_frequencies(딕셔너리)
#딕셔너리는 key가 단어, value로는 해당 단어의 빈도 수인 딕셔너리어야한다.
아래와 같은 과정을 통해서 워드 클라우드를 만들고 화면상에 출력할 수 있다.
#워드클라우드 만들기
from wordcloud import WordCloud
wc = WordCloud(background_color="white", max_font_size=60)
cloud = wc.generate_from_frequencies(tk.word_counts)
#워드클라우드 출력하기
from matplotlib import pyplot as plt
plt.imshow(cloud)
plt.show()

다만 이렇게 진행했을 경우, 위와 같이 한글이 깨지는 문제가 발생한다.
왜냐하면 캐글의 주피터노트북은 한글폰트가 기본으로 설치가 되어있지 않기 때문이다.
그러므로 한글폰트를 다운로드하여 한글폰트경로를 지정해주어야 한다.
한글 깨짐 오류 해결하기
1.한글폰트 설치 및 경로 찾기
#깃허브로부터 나눔폰트 다운로드
!git clone https://github.com/namepen/nanum_font.git
#다운받은 폰트 경로 찾기
import matplotlib.font_manager as font_manager
font_dirs = ['nanum_font', ]
font_files = font_manager.findSystemFonts(fontpaths=font_dirs)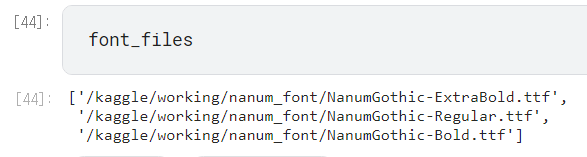
설치한 폰트의 경로를 찾았다.
2. 한글폰트 적용하여 워드클라우드 만들기
from matplotlib import pyplot as plt
wc2 = WordCloud(font_path='/kaggle/working/nanum_font/NanumGothic-Regular.ttf',
background_color="white",
max_font_size=120,
width=400,
height=200)
cloud2 = wc2.generate_from_frequencies(dict(sorted_Words))
plt.figure()
plt.imshow(cloud2)
plt.axis('off')
plt.show()이런 식으로 실행이 잘 되는 것이 확인가능하다.

클라우드에 나올 단어 수 조절하기
만약에, 단어가 너무 많아서 빽빽한 게 보기 싫은 경우,
워드 클라우드에 사용하는 단어들의 수를 조절할 수 있다.
sorted()를 사용해서 Tokenizer의 word_counts로부터 얻은 딕셔너리를 단어 출현빈도가 높은 순서대로 정렬 후,
상위 몇 개 까지 추가할 것인지 결정하고 이를 워드클라우드에 넣어주면 된다.
1. sorted()로 단어 출현 빈도수에 따라 정렬하기
그냥 sorted(딕셔너리)를 사용할 경우 딕셔너리의 value가 아니라 key 값에 의해 정렬이 되는 문제가 있다.
우리가 사용할 딕셔너리는 단어:출현빈도수 꼴이므로 출현빈도수를 기준으로 정렬하고자 하려면
sorted의 key와 람다식을 사용해 정렬할 때 어떤 값을 기준으로 할지를 정해주면 된다.
sorted_Words = (sorted(words.items(),key= lambda x:x[1],reverse=True))
*sorted는 기본적으로 오름차순으로 정렬하므로 reverse=True를 하여 내림차순으로 정렬하여야 한다
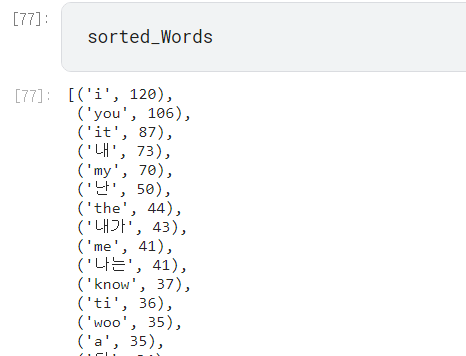
실행 결과, 튜플 리스트로 정렬이 잘된 것을 확인이 가능하다.
2.원하는 만큼 단어 잘라내기
위 작업에서 얻은 정렬된 튜플리스트를 상위 50개까지만 잘라내도록 하겠다.
sorted_Words = (sorted(words.items(),key= lambda x:x[1],reverse=True))
sorted_Words50 =sorted_Words[:50]
len(sorted_Words50)실행결과, 잘 잘린 것을 확인할 수 있다.

3.워드클라우드에 집어넣기
워드클라우드는 딕셔너리만 입력으로 받으므로 딕셔너리로 바꾸어 주어야 한다
튜플리스트는 dict()으로 간단하게 딕셔너리로 전환하는 것이 가능하다.
from wordcloud import WordCloud
wc2 = WordCloud(font_path='/kaggle/working/nanum_font/NanumGothic-Regular.ttf',
background_color="white",
max_font_size=120,
width=400,
height=200)
cloud2 = wc2.generate_from_frequencies(dict(sorted_Words50))
from matplotlib import pyplot as plt
plt.figure()
plt.imshow(cloud2)
plt.axis('off')
plt.show()
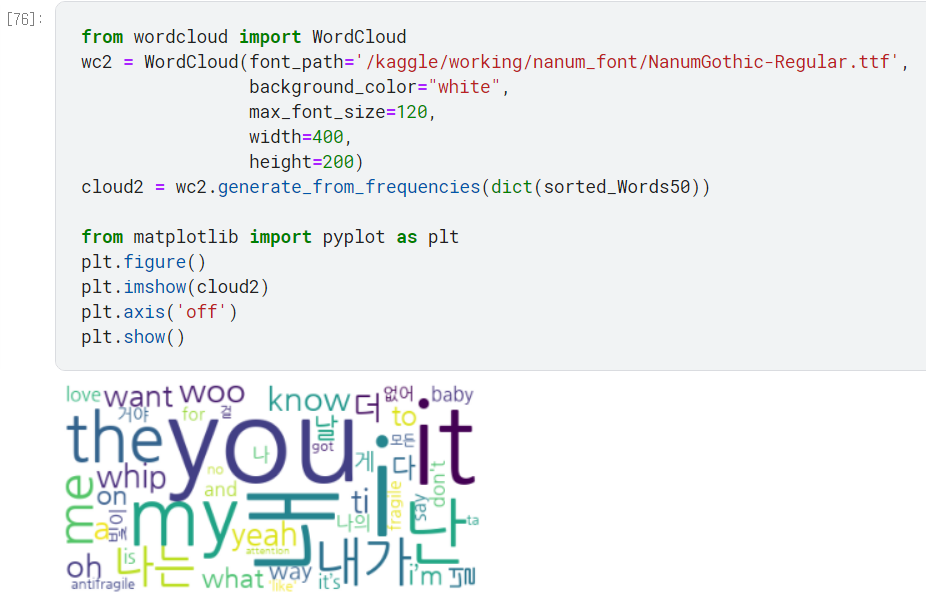
아까 전과 비교해 단어 수가 줄어들어 여백이 커진 것을 확인이 가능하다.
참조
https://ko.wikipedia.org/wiki/%ED%83%9C%EA%B7%B8_%ED%81%B4%EB%9D%BC%EC%9A%B0%EB%93%9C
태그 클라우드 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 태그 클라우드(영어: tag cloud) 또는 워드 클라우드(word cloud)는 메타 데이터에서 얻어진 태그들을 분석하여 중요도나 인기도 등을 고려하여 시각적으로 늘어 놓
ko.wikipedia.org
https://github.com/namepen/nanum_font
GitHub - namepen/nanum_font: 네이버 나눔 폰트를 저장하여 불러오기 위한 저장소입니다.
네이버 나눔 폰트를 저장하여 불러오기 위한 저장소입니다. Contribute to namepen/nanum_font development by creating an account on GitHub.
github.com
https://korbillgates.tistory.com/171
[python] 파이썬 사전 딕셔너리 값 value 로 정렬하는 방법 - lambda 식 응용 - 파이썬으로 단어 수 세기
안녕하세요 한주현입니다. 오늘은 python에서 딕셔너리의 값으로 정렬하는 방법에 대해 알아보겠습니다. 들어가며 python 의 사전형은 순서가 없는 자료형입니다. 그런데 가끔 우리는 사전의 값 순
korbillgates.tistory.com
'개인프로젝트' 카테고리의 다른 글
| [홈서버]나는 홈서버를 왜 만들게 되었는가? - 나만의 서버 구축기 #0.5 (0) | 2025.03.22 |
|---|---|
| [홈서버]홈 서버란 무엇인가? - 나만의 서버 구축기 #0 (2) | 2025.03.20 |
| [Python]멜론 노래 가사 추출하기(4)_수집한 데이터 가공하기 with 캐글 (0) | 2023.01.05 |
| [Python]멜론 노래 가사 추출하기(3)_셀레니움으로 노래가사 찾기 with 캐글 (4) | 2023.01.04 |
| [Python]멜론 노래 가사 추출하기(2)_셀레니움은 어떻게 요소들을 찾는가? with 캐글 (2) | 2023.01.02 |



