저번시간에는 활성화 함수를 실제 코드로 사용할 방법에 대해 알아보았었다.
이번시간에는 Pooling이란 무엇이며 왜 사용하는지 그리고 종류와 사용법에 대해 알아보도록 하겠다.
Pooling은 무엇이며 왜 사용하는가?
풀링은 입력된 이미지(데이터)에 대한 축소본을 만드는 것이다.
풀링을 사용하는 이유로는 여러 가지가 있는데, 먼저 풀링을 하면 파라미터의 수(데이터의 크기)를 줄여 연산량이 적어지며 과적합을 방지한다는 장점이 있기 때문이다.
또한 풀링 과정을 거치면 Feature Map에서 특징을 잘 뽑아내서 노이즈에 강해지기 때문이다.
하지만 장점만 있는 것이 아니다. 데이터의 크기를 줄이기 때문에 과하게 사용하면 입력 데이터의 막대한 소실로 이어지기 때문이다.
그러므로 적재적소에 알맞게 사용하여야 한다.
풀링에는 MaxPooling, AveragePooling, GlobalAveragePooling 총 3가지가 있다.
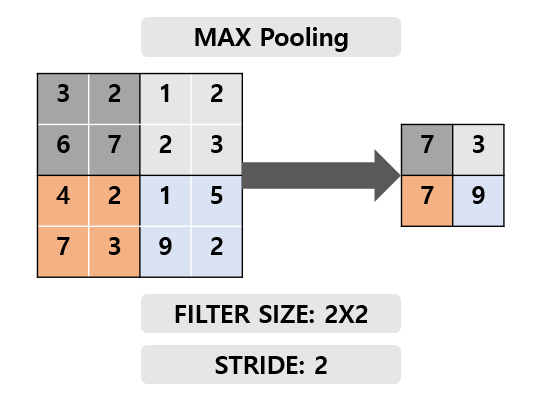
MaxPooling
MaxPooling은 필터(커널) 내의 값 중 가장 큰 값을 가져온다.
코드
from tensorflow.keras.layers import MaxPooling2D
MaxPooling2D(pool_size=(2,2), strides=None, padding="valid", data_format="channels_last")
파라미터
| pool_size | 필터(커널)의 사이즈. 튜플의 형태(수평크기,수직크기)로 쓰이거나 수직 수평 크기가 같다면 정수로 쓰임. |
| strides | 필터의 이동거리인 stride 값을 정해준다. 튜플의 형태로 쓰이나 수직 수평 이동거리가 같다면 정수로도 사용가능하다. 기본 값은 pool_size와 동일하게 설정된다. |
| padding | 패딩의 설정. valid는 패딩 없음, same은 패딩이 있어 데이터의 크기가 그대로 유지됨. 기본적으로 valid로 설정되어있다. |
| data_format | 데이터 형식의 지정. channels_last 는 (batch,height, width, channels), channels_first 는 (batch, channels, height, width) 기본적으로 channels_last로 설정되어있다. *예를들어 2000개의 (32,32,3)의 이미지가 있다면 channels_last는 입력 데이터 형태를 (2000,32,32,3) 으로 받겠다는 뜻이며 channels_first는 입력 데이터 형태를 (2000,3,32,32) 으로 받겠다는 의미이다. |
AveragePooling
AveragePooling은 필터(커널) 내 원소들의 평균을 가져온다.

코드
AveragePooling2D 또한 MaxPooling2D와 파라미터가 전부 동일하다.
from tensorflow.keras.layers import AveragePooling2D
AveragePooling2D(pool_size=(2,2), strides=None, padding="valid", data_format="channels_last")
파라미터
| pool_size | 필터(커널)의 사이즈. 튜플의 형태(수평크기,수직크기)로 쓰이거나 수직 수평 크기가 같다면 정수로 쓰임. |
| strides | 필터의 이동거리인 stride 값을 정해준다. 튜플의 형태로 쓰이나 수직 수평 이동거리가 같다면 정수로도 사용가능하다. 기본 값은 pool_size와 동일하게 설정된다. |
| padding | 패딩의 설정. valid는 패딩 없음, same은 패딩이 있어 데이터의 크기가 그대로 유지됨. 기본적으로 valid로 설정되어있다. |
| data_format | 입력 데이터 형식의 지정. channels_last 는 (batch,height, width, channels), channels_first 는 (batch, channels, height, width) 기본적으로 channels_last로 설정되어있다. *예를들어 2000개의 (32,32,3)의 이미지가 있다면 channels_last는 입력 데이터 형태를 (2000,32,32,3) 으로 받겠다는 뜻이며 channels_first는 입력 데이터 형태를 (2000,3,32,32) 으로 받겠다는 의미이다. |
GlobalAeragePooling
GlobalAveragePooling, 일명 GAP는 두 풀링과는 달리 한 FeatureMap에서가 아니라 각 Feature Map에서 평균을 가져온다.
데이터의 크기가 매우 극단적으로 줄어들지만 출력층의 Dense 층 대신 사용되기도 한다.

코드
from tensorflow.keras.layers import GlobalMaxPooling2D
GlobalMaxPooling2D(data_format="channels_last", keepdims=False)
파라미터
| data_format | 입력 데이터 형식의 지정. channels_last 는 (batch,height, width, channels), channels_first 는 (batch, channels, height, width) 기본 값은 channels_last 이다. *예를 들어 2000개의 (32,32,3)의 이미지가 있다면 channels_last는 입력 데이터 형태를 (2000,32,32,3) 으로 받겠다는 뜻이며 channels_first는 입력 데이터 형태를 (2000,3,32,32) 으로 받겠다는 의미이다. |
| keepdims | 데이터의 차원 유지 여부. True일 경우 입력데이터의 차원이 유지되고 False 일 경우 차원이 낮아진다. 기본값은 False 이다 *예를 들어, (2000,32,32,3) 크기의 입력이 들어 왔을 때 keepdims가 True 일 경우 출력의 형태는 (2000,1,1,3)이 된다. False 일 경우 출력의 형태는 (2000,3) 이 된다. |
이번시간엔 풀링의 의미, 사용이유, 그리고 사용 방법에 대해 알아보았다.
혹시 더욱 궁금한 점이 있거나 잘못된 부분이 있다면 자유롭게 댓글을 통해 알려주세요!
참조
https://keras.io/api/layers/pooling_layers/
Keras documentation: Pooling layers
keras.io
'수업내용정리 > 인공지능' 카테고리의 다른 글
| [SckitLearn]지도학습 알고리즘(2)_선형 SVM 분류기의 특징과 사용법 (0) | 2023.02.13 |
|---|---|
| [SckitLearn]지도학습 알고리즘(1)_의사결정트리의 특징과 사용법 (0) | 2023.02.11 |
| tensorflow.keras.activations 활성화 함수 모델에서 사용하기 (0) | 2023.02.07 |
| [Tensorflow][Keras]활성화 함수 코드로 알아보기 (0) | 2023.02.05 |
| [인공지능]활성화 함수의 종류 알아보기 (0) | 2023.01.20 |



