저번 시간에는 개략적으로 인공지능, 머신러닝, 딥러닝에 대해 살펴보았습니다. 이번시간에는 머신러닝 중에서도 지도학습 알고리즘인 의사결정트리에 대해 알아보도록 하겠습니다.
의사결정트리(Decision Tree)란?
결정트리(Decision Tree)는 머신러닝 알고리즘 중 하나이다.
분류, 회귀 작업이 모두 가능하다.
스케일을 맞추는 것과 같은 전처리가 거의 필요 없는 특징이 있다.

위 그림은 sklearn.datasets의 iris 데이터를 가지고 DecisionTreeClassifier가 만든 트리이다. (깊이가 2인 결정트리)
색칠된 노드들은 말단노드로서 분류의 최종값이다.
samples 는 해당 노드에 속한 샘플들의 수이다.
value는 각 클래스별 샘플들의 수이다.
class는 결정트리가 예측한 클래스이다.
위처럼 어떠한 특징을 가지고 기준값에 따라 질문을 하여 예측을 하는 머신러닝 알고리즘을 DecisionTree 라고한다.
그렇다면 이러한 트리는 어떻게 만들어지는가?
지니 불순도를 활용하여 트리에서 특성과 임계값을 고른다.
지니 불순도란?
결정 트리에서 불순도를 측정하는 데 사용된다.
한 노드에서 모든 샘플들이 같은 클래스라면 지니 불순도는 0이 된다.
k개의 클래스가 존재하는 샘플들 중에서, i 번째 노드에서의 지니 불순도는 다음과 같이 계산된다.
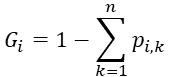
p_(i, k)는 i번째 노드에서 클래스 k에 속한 샘플의 비율을 의미한다.
ex) 위 트리 그림의 초록색 말단 노드(leaf node)의 지니 불순도는 아래와 같이 계산된다.

의사결정트리 사용법
이러한 의사결정트리를 사용하고자 하면 아래 코드를 따라 사용하면 된다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = load_iris()
#test, train 분리
X_train, X_test, y_train, y_test = train_test_split(iris.data[:,2:], iris.target)
#깊이 2의 트리(다른 데이터에 대해 사용시 max_depth를 적당히 조절하여 사용하는 것이 좋다)
tree = DecisionTreeClassifier(max_depth=2)
#훈련
tree.fit(X_train,y_train)
#예측 및 결과 확인
y_pred = tree.predict(X_test)
print(accuracy_score(y_test,y_pred))
참조
Geron, Aurelien, 박해선 역, 핸즈온 머신러닝, 한빛미디어, 2020
'수업내용정리 > 인공지능' 카테고리의 다른 글
| [SckitLearn]지도학습 알고리즘(3)_비선형 SVM 분류기의 특징과 사용법 (0) | 2023.02.14 |
|---|---|
| [SckitLearn]지도학습 알고리즘(2)_선형 SVM 분류기의 특징과 사용법 (0) | 2023.02.13 |
| [Tensorflow][Keras]Pooling 의 종류 및 사용법_ CNN이란? (0) | 2023.02.08 |
| tensorflow.keras.activations 활성화 함수 모델에서 사용하기 (0) | 2023.02.07 |
| [Tensorflow][Keras]활성화 함수 코드로 알아보기 (0) | 2023.02.05 |



